当一群 Claude 上场:Anthropic 多智能体系统深读 + 全文译介
原文地址:https://www.anthropic.com/engineering/built-multi-agent-research-system
必读推荐:当一群 Claude 上场——它远不止一篇 AI 系统介绍
初看标题,你可能会以为这只是 Anthropic 的又一篇技术炫耀文。但请相信我,如果你是一名软件工程师——尤其是像我们一样,在云计算和分布式系统的泥潭里摸爬滚打过的工程师——这篇文章的价值,远远超出了“多 agent”这个时髦词汇本身。
我们和 Gemini 一起逐句精读并翻译了全文,越读越心惊。这根本不是一篇 AI 论文,而是一份将经典、严谨的现代软件工程思想,注入到 AI Agent 这个全新、混沌领域的“施工蓝图”。
它是一面双面镜,值得你从两个角度细品:
一面,是 AI Agent 的前沿实践。 你会看到:
- “智能版 MapReduce”: 主 agent 如同 Mapper 分解任务,子 agent 如同 Reducer 并行处理、压缩信息。这套我们烂熟于心的分布式思想,被优雅地应用在了充满不确定性的“语义空间”。
- Prompt 即代码: 提示词不再是随口的魔法咒语,而是需要被版本控制、迭代优化、甚至 A/B 测试的工程产物。它就是 agent 时代的配置文件和业务逻辑。
- 为混沌系统建立仪表盘: 面对 agent 的不确定性,Anthropic 正在探索全新的 SRE 范式——通过可观察性、追踪和评估,为这个“混沌系统”建立信任和纠错的可能。
另一面,是现代软件工程架构规范的“最佳实践复习题”。 它会逼你重新思考:
- 认知资源的 ROI:
multi-agent系统的token消耗是普通聊天的 15 倍。这意味着,每一次调用“AI 军团”都是一次昂贵的决策。架构设计,首次与任务的“商业价值”如此紧密地绑定。你的每一次技术选型,都是一次产品和商业上的价值判断。 - 从“能做”到“值得做”: 这篇文章的核心,在教我们抑制技术上的“炫技冲动”,回归工程的本质——用恰如其分的成本,解决有足够价值的问题。
- 工业化生产的纪律: 从错误处理、失败恢复,到“彩虹部署”,这些我们云平台工程师天天挂在嘴边的“脏活累活”,如今成了 AI 系统从“炼丹炉”走向“化工厂”的基石。
一个 Alpha Moment 的思考:
读完此文,我们最大的感触是工程师角色的演变。过去,我们是确定性机器的建造者,我们写下的每一行代码,逻辑都如齿轮般精确。
而现在,我们正在成为非确定性智能体的“生态园丁”。
我们的工作,不再是精确指令机器“向左转,走三步”,而是为一群“聪明的、但有点野的” agent 创造一个能茁壮成长的生态环境:我们提供土壤和工具(Tools)、设定生长规则(Prompts & Guardrails)、观察并修剪枝叶(Evaluation & Human-in-the-loop),并设计它们之间的协作机制(Orchestration)。
这种从“造机器”到“养生态”的转变,对我们的思维模式和技能栈提出了全新的、令人兴奋的要求。
所以,强烈推荐你花时间通读这篇文章(以及我们协作完成的这份译文)。它不仅能让你理解顶尖公司对 multi-agent 系统的思考深度,更能让你对自己作为一名软件工程师的未来,产生全新的、或许是颠覆性的认知。
原文+翻译
Published Jun 13, 2025 发布于 2025 年 6 月 13 日
How we built our multi-agent research system 我们如何构建 multi-agent 研究系统
Our Research feature uses multiple Claude agents to explore complex topics more effectively. We share the engineering challenges and the lessons we learned from building this system.
我们的研究(Research)功能通过协同多个 Claude agent,来更高效地探索复杂主题。在此,我们愿分享构建此系统时所遇到的工程挑战与习得的经验教训。
Claude now has Research capabilities that allow it to search across the web, Google Workspace, and any integrations to accomplish complex tasks.
Claude 现已具备研究(Research)能力,能够横跨 Web、Google Workspace 及各类集成应用进行搜索,以应对复杂任务。
The journey of this multi-agent system from prototype to production taught us critical lessons about system architecture, tool design, and prompt engineering. A multi-agent system consists of multiple agents (LLMs autonomously using tools in a loop) working together. Our Research feature involves an agent that plans a research process based on user queries, and then uses tools to create parallel agents that search for information simultaneously. Systems with multiple agents introduce new challenges in agent coordination, evaluation, and reliability.
将这个 multi-agent 系统从原型推向生产的历程,让我们在系统架构、工具设计和提示工程方面收获了宝贵的经验。所谓 multi-agent 系统,即由多个 agent(在循环中自主使用工具的 LLM)协同工作。我们的“研究”功能包含一个“主 agent”,它会根据用户查询规划研究流程,并使用工具创建多个“并行 agent”来同步搜索信息。这种多 agent 系统在协调、评估和可靠性方面都带来了新的挑战。
This post breaks down the principles that worked for us—we hope you’ll find them useful to apply when building your own multi-agent systems.
本文将剖析一些对我们行之有效的原则,希望能为正在构建 multi-agent 系统的你带来启发。
Benefits of a multi-agent system 多 agent 系统的好处
Research work involves open-ended problems where it’s very difficult to predict the required steps in advance. You can’t hardcode a fixed path for exploring complex topics, as the process is inherently dynamic and path-dependent. When people conduct research, they tend to continuously update their approach based on discoveries, following leads that emerge during investigation.
研究工作涉及开放性问题,事先很难预测所需的步骤。你无法为探索复杂主题硬编码一条固定路径,因为这个过程本质上是动态的,并且依赖于路径。当人们进行研究时,他们往往会根据发现不断更新他们的方法,跟随在调查过程中出现的线索。
This unpredictability makes AI agents particularly well-suited for research tasks. Research demands the flexibility to pivot or explore tangential connections as the investigation unfolds. The model must operate autonomously for many turns, making decisions about which directions to pursue based on intermediate findings. A linear, one-shot pipeline cannot handle these tasks.这种不可预测性,使得 AI agent 尤为胜任研究类任务。研究工作要求在探索过程中随时调整方向或探寻衍生线索,这需要高度的灵活性。模型必须能够多轮次地自主运行,并依据中间结论来决定后续的探索方向。线性的、一次性的处理流水线(linear, one-shot pipeline)无法胜任此类任务。
The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing the most important tokens for the lead research agent. Each subagent also provides separation of concerns—distinct tools, prompts, and exploration trajectories—which reduces path dependency and enables thorough, independent investigations.
搜索的本质是信息压缩:即从海量语料中萃取洞见。子 agent (Subagents) 通过其独立的上下文窗口并行运作,促进了这一压缩过程。它们同步探索问题的不同侧面,最终将最重要的信息 (tokens) 提炼并交给主研究 agent。同时,每个子 agent 实现了“关注点分离”(separation of concerns)——拥有独立的工具、提示和探索路径,这降低了路径依赖,使系统得以进行更彻底、独立的调查。
Once intelligence reaches a threshold, multi-agent systems become a vital way to scale performance. For instance, although individual humans have become more intelligent in the last 100,000 years, human societies have become exponentially more capable in the information age because of our collective intelligence and ability to coordinate. Even generally-intelligent agents face limits when operating as individuals; groups of agents can accomplish far more.
一旦智能达到一个阈值,multi-agent 系统就成为扩展性能的重要方式。例如,尽管个体人类在过去的 10 万年中变得更加聪明,但由于我们的集体智能和协调能力,人类社会在信息时代变得指数级更有能力。即使是一般智能的 agent 在作为个体操作时也面临限制;agent 组可以完成更多的任务。
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously. We found that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval. For example, when asked to identify all the board members of the companies in the Information Technology S&P 500, the multi-agent system found the correct answers by decomposing this into tasks for subagents, while the single agent system failed to find the answer with slow, sequential searches.我们的内部评估显示,multi-agent 研究系统在处理涉及同时追求多个独立方向的广度优先查询时表现尤为出色。一个由 Claude Opus 4 担任主 agent、Claude Sonnet 4 担任子 agent 的 multi-agent 系统,在内部研究评估中的表现比单 agent 的 Claude Opus 4 高出 90.2%。例如,当被要求识别信息技术 S&P 500 中所有公司的董事会成员时,multi-agent 系统通过将任务分解给子 agent 找到了正确答案,而单 agent 系统则因缓慢的顺序搜索未能找到答案。
Multi-agent systems work mainly because they help spend enough tokens to solve the problem. In our analysis, three factors explained 95% of the performance variance in the BrowseComp evaluation (which tests the ability of browsing agents to locate hard-to-find information). We found that token usage by itself explains 80% of the variance, with the number of tool calls and the model choice as the two other explanatory factors. This finding validates our architecture that distributes work across agents with separate context windows to add more capacity for parallel reasoning. The latest Claude models act as large efficiency multipliers on token use, as upgrading to Claude Sonnet 4 is a larger performance gain than doubling the token budget on Claude Sonnet 3.7. Multi-agent architectures effectively scale token usage for tasks that exceed the limits of single agents.
multi-agent 系统之所以有效,主要是因为它们有助于消耗足够的 token 来解决问题。在我们的分析中,有三个因素解释了 BrowseComp 评估中 95% 的性能差异(该评估测试浏览 agent 定位难以找到的信息的能力)。我们发现,仅 token 使用本身就解释了 80% 的差异,工具调用次数和模型选择是另外两个解释性因素。这一发现验证了我们的架构设计:通过独立的上下文窗口将工作分发给不同 agent,从而为并行推理扩容。最新的 Claude 模型在 token 使用上充当了大型效率倍增器,因为升级到 Claude Sonnet 4 的性能提升大于将 Claude Sonnet 3.7 的 token 预算翻倍。对于超出单个 agent 能力极限的任务,multi-agent 架构能有效地扩展 token 的使用规模。
There is a downside: in practice, these architectures burn through tokens fast. In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance. Further, some domains that require all agents to share the same context or involve many dependencies between agents are not a good fit for multi-agent systems today. For instance, most coding tasks involve fewer truly parallelizable tasks than research, and LLM agents are not yet great at coordinating and delegating to other agents in real time. We’ve found that multi-agent systems excel at valuable tasks that involve heavy parallelization, information that exceeds single context windows, and interfacing with numerous complex tools.
但这种架构也有其弊端:在实践中,它消耗 token 的速度极快。我们的数据显示,单个 agent 交互所用的 token 量约是普通聊天的 4 倍,而 multi-agent 系统更是高达 15 倍。从经济角度看,multi-agent 系统需要应用于那些价值足够高、能够覆盖其性能成本的任务上。此外,对于需要所有 agent 共享同一上下文、或 agent 间存在强依赖关系的领域,目前的 multi-agent 系统并非理想选择。例如,多数编码任务的可并行度低于研究任务,且目前的 LLM agent 在实时协调与任务委派方面尚不成熟。我们发现,multi-agent 系统在以下类型的高价值任务中表现卓越:需要大规模并行处理、信息量超越单个上下文窗口、以及需要与大量复杂工具交互的任务。
Architecture overview for Research 研究功能架构概述
Our Research system uses a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process while delegating to specialized subagents that operate in parallel.
我们的研究系统采用了一种 multi-agent 架构,其模式为“协调者-工作者”(orchestrator-worker),其中一个主 agent 负责协调流程,同时将任务委派给并行运作的专业子 agent。
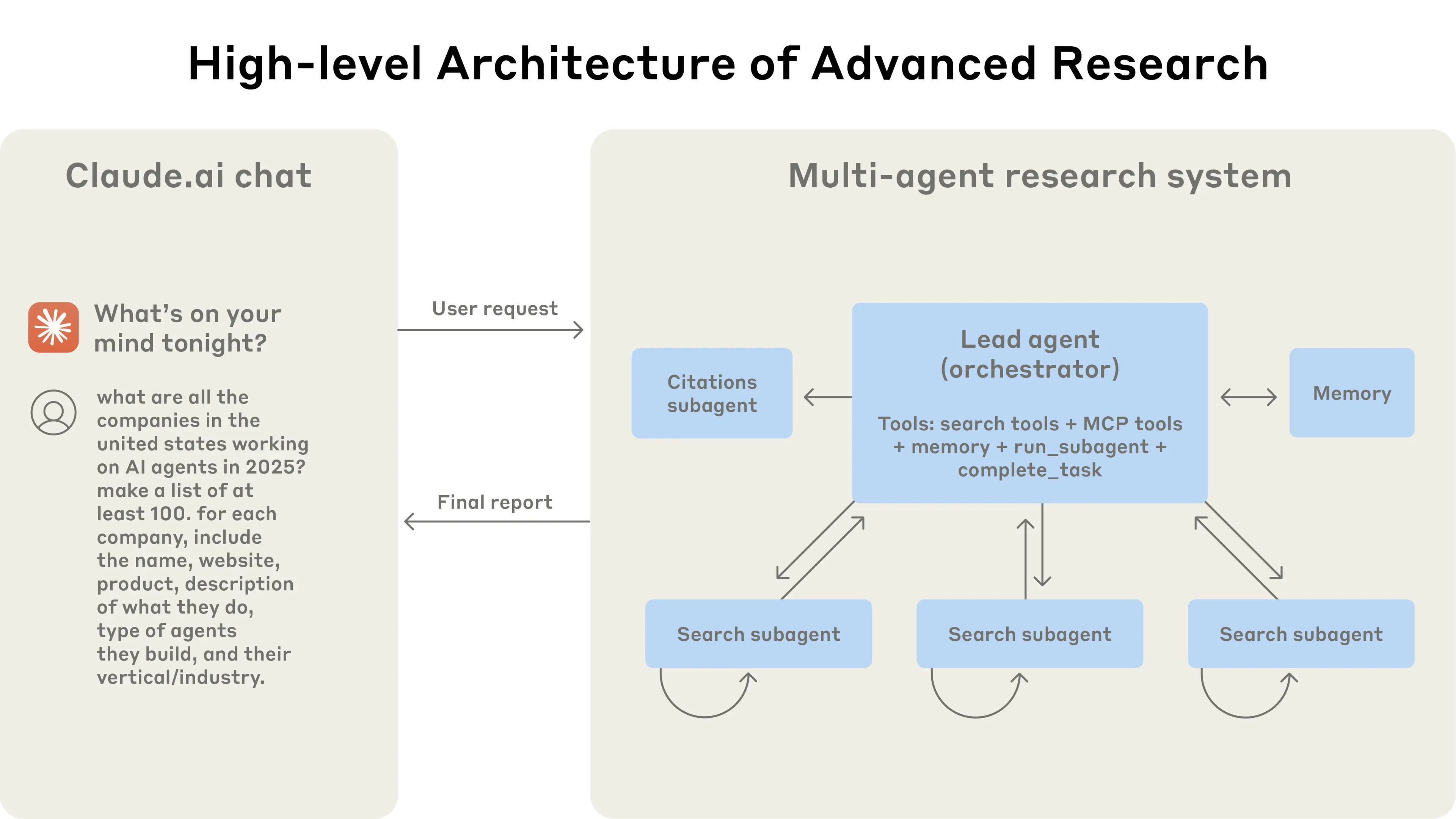
When a user submits a query, the lead agent analyzes it, develops a strategy, and spawns subagents to explore different aspects simultaneously. As shown in the diagram above, the subagents act as intelligent filters by iteratively using search tools to gather information, in this case on AI agent companies in 2025, and then returning a list of companies to the lead agent so it can compile a final answer.
当用户提交查询时,主 agent 会分析该查询,制定策略,并生成子 agent 以同时探索不同的方面。如上图所示,子 agent 扮演着智能过滤器的角色,通过迭代使用搜索工具收集信息(本例中是关于 2025 年的 AI agent 公司),然后将公司列表返回给主 agent,以便其汇编最终答案。
Traditional approaches using Retrieval Augmented Generation (RAG) use static retrieval. That is, they fetch some set of chunks that are most similar to an input query and use these chunks to generate a response. In contrast, our architecture uses a multi-step search that dynamically finds relevant information, adapts to new findings, and analyzes results to formulate high-quality answers.
传统的检索增强生成(RAG)方法使用静态检索。也就是说,它们获取与输入查询最相似的一组文本块(chunks),并利用这些文本块生成响应。相比之下,我们的架构使用多步搜索,能动态地寻找相关信息,适应新发现,并分析结果以形成高质量的答案。

Prompt engineering and evaluations for research agents 研究 agent 的提示工程与评估
Multi-agent systems have key differences from single-agent systems, including a rapid growth in coordination complexity. Early agents made errors like spawning 50 subagents for simple queries, scouring the web endlessly for nonexistent sources, and distracting each other with excessive updates. Since each agent is steered by a prompt, prompt engineering was our primary lever for improving these behaviors. Below are some principles we learned for prompting agents:
multi-agent 系统与单 agent 系统有关键区别,包括协调复杂性的快速增长。早期的 agent 曾犯过诸如为简单查询生成 50 个子 agent、无休止地在网络上搜索不存在的来源,以及通过过多的更新相互干扰之类的错误。由于每个 agent 都由提示引导,提示工程(prompt engineering)成为我们改善这些行为的主要手段。以下是我们为提示 agent 所学到的一些原则:
Think like your agents. 像你的 agent 一样思考
To iterate on prompts, you must understand their effects. To help us do this, we built simulations using our Console with the exact prompts and tools from our system, then watched agents work step-by-step. This immediately revealed failure modes: agents continuing when they already had sufficient results, using overly verbose search queries, or selecting incorrect tools. Effective prompting relies on developing an accurate mental model of the agent, which can make the most impactful changes obvious.
要对提示进行迭代,你必须理解它们的效果。为此,我们使用控制台(Console)和系统中的确切提示及工具来构建模拟,然后逐步观察 agent 的工作。这立即揭示了失败模式:agent 在已获得足够结果时仍继续执行,使用过于冗长的搜索查询,或选择错误的工具。有效的提示依赖于建立对 agent 的准确心智模型,这能让最具影响力的改变变得显而易见。
Teach the orchestrator how to delegate. 教会“协调者”(Orchestrator)如何委派任务
In our system, the lead agent decomposes queries into subtasks and describes them to subagents. Each subagent needs an objective, an output format, guidance on the tools and sources to use, and clear task boundaries. Without detailed task descriptions, agents duplicate work, leave gaps, or fail to find necessary information. We started by allowing the lead agent to give simple, short instructions like ‘research the semiconductor shortage,’ but found these instructions often were vague enough that subagents misinterpreted the task or performed the exact same searches as other agents. For instance, one subagent explored the 2021 automotive chip crisis while 2 others duplicated work investigating current 2025 supply chains, without an effective division of labor.
在我们的系统中,主 agent 将查询分解为子任务并向子 agent 描述它们。每个子 agent 都需要一个目标、一种输出格式、关于使用何种工具和信源的指导,以及明确的任务边界。没有详细的任务描述,agent 就会重复工作、留下空白或找不到必要信息。例如,一个子 agent 在探索 2021 年的汽车芯片危机,而另外两个则在重复调查当前 2025 年的供应链,没有有效的劳动分工。
Scale effort to query complexity. 让投入的资源与查询复杂度相匹配
Agents struggle to judge appropriate effort for different tasks, so we embedded scaling rules in the prompts. Simple fact-finding requires just 1 agent with 3-10 tool calls, direct comparisons might need 2-4 subagents with 10-15 calls each, and complex research might use more than 10 subagents with clearly divided responsibilities. These explicit guidelines help the lead agent allocate resources efficiently and prevent overinvestment in simple queries, which was a common failure mode in our early versions.
agent 在判断不同任务所需的适当投入时会遇到困难,因此我们在提示中嵌入了扩展规则。简单的事实查找只需 1 个 agent 进行 3-10 次工具调用;直接比较可能需要 2-4 个子 agent,每个进行 10-15 次调用;而复杂的研究可能需要超过 10 个责任分工明确的子 agent。这些明确的指导方针帮助主 agent 有效分配资源,防止在简单查询上过度投资…
Tool design and selection are critical. 工具设计和选择至关重要
Agent-tool interfaces are as critical as human-computer interfaces. Using the right tool is efficient—often, it’s strictly necessary. For instance, an agent searching the web for context that only exists in Slack is doomed from the start. With MCP servers that give the model access to external tools, this problem compounds, as agents encounter unseen tools with descriptions of wildly varying quality. We gave our agents explicit heuristics: for example, examine all available tools first, match tool usage to user intent, search the web for broad external exploration, or prefer specialized tools over generic ones. Bad tool descriptions can send agents down completely wrong paths, so each tool needs a distinct purpose and a clear description.
agent 与工具的接口和人机接口同样重要。使用正确的工具是高效的——通常,这也是绝对必要的。例如,一个 agent 试图在网络上搜索仅存在于 Slack 中的上下文,从一开始就注定要失败。有了能让模型访问外部工具的 MCP 服务器,这个问题变得更加复杂,因为 agent 会遇到各种描述质量参差不齐的未知工具。我们为 agent 提供了明确的启发式规则:例如,首先检查所有可用工具,将工具使用与用户意图相匹配,为广泛的外部探索而搜索网络,或优先选择专业工具而非通用工具。糟糕的工具描述可能会使 agent 走上完全错误的道路,因此每个工具都需要有明确的目的和清晰的描述。
Let agents improve themselves. 让 agent 自我改进
We found that the Claude 4 models can be excellent prompt engineers. When given a prompt and a failure mode, they are able to diagnose why the agent is failing and suggest improvements. We even created a tool-testing agent—when given a flawed MCP tool, it attempts to use the tool and then rewrites the tool description to avoid failures. By testing the tool dozens of times, this agent found key nuances and bugs. This process for improving tool ergonomics resulted in a 40% decrease in task completion time for future agents using the new description, because they were able to avoid most mistakes.
我们发现 Claude 4 模型可以成为优秀的提示工程师。当给定一个提示和一个失败模式时,它们能够诊断 agent 失败的原因并提出改进建议。我们甚至创建了一个工具测试 agent——当给定一个有缺陷的 MCP 工具时,它会尝试使用该工具,然后重写其描述以避免失败。通过对该工具进行数十次测试,这个 agent 发现了关键的细微差别和 bug。这个改善工具人机工程学的过程,使得未来使用新描述的 agent 在任务完成时间上减少了 40%,因为它们能够避免大多数错误。
Start wide, then narrow down. 先广后精,由宽入窄
Search strategy should mirror expert human research: explore the landscape before drilling into specifics. Agents often default to overly long, specific queries that return few results. We counteracted this tendency by prompting agents to start with short, broad queries, evaluate what’s available, then progressively narrow focus.
搜索策略应当效仿人类专家的研究方式:在深入具体细节之前,先探索整体概貌。agent 通常倾向于使用过于冗长、具体的查询,但这只会返回很少的结果。我们通过提示 agent 从简短、广泛的查询开始,评估可用信息,然后逐步缩小焦点,来抵消这种倾向。
Guide the thinking process. 引导思维过程
Extended thinking mode, which leads Claude to output additional tokens in a visible thinking process, can serve as a controllable scratchpad. The lead agent uses thinking to plan its approach, assessing which tools fit the task, determining query complexity and subagent count, and defining each subagent’s role. Our testing showed that extended thinking improved instruction-following, reasoning, and efficiency. Subagents also plan, then use interleaved thinking after tool results to evaluate quality, identify gaps, and refine their next query. This makes subagents more effective in adapting to any task.
“扩展思维模式”(Extended thinking mode)能引导 Claude 在一个可见的思维过程中输出额外的 token,可作为一个可控的草稿纸。主 agent 使用思维来规划其方法,评估哪些工具适合任务,确定查询复杂度和子 agent 数量,并定义每个子 agent 的角色。我们的测试表明,扩展思维提高了指令遵循、推理和效率。子 agent 也会进行规划,然后在得到工具结果后使用“交错思维”(interleaved thinking)来评估质量、识别差距并完善下一个查询。这使得子 agent 在适应任何任务时更加有效。
Parallel tool calling transforms speed and performance. 并行工具调用:速度与性能的变革
Complex research tasks naturally involve exploring many sources. Our early agents executed sequential searches, which was painfully slow. For speed, we introduced two kinds of parallelization: (1) the lead agent spins up 3-5 subagents in parallel rather than serially; (2) the subagents use 3+ tools in parallel. These changes cut research time by up to 90% for complex queries, allowing Research to do more work in minutes instead of hours while covering more information than other systems.
复杂的研究任务自然涉及探索多个来源。我们早期的 agent 执行顺序搜索,这非常缓慢。为了提速,我们引入了两种并行化方式:(1)主 agent 并行启动 3-5 个子 agent,而非串行;(2)子 agent 并行使用 3 个以上的工具。这些变化将复杂查询的研究时间削减了高达 90%,使得研究功能(Research)能在数分钟内完成以往需要数小时的工作,同时覆盖比其他系统更广的信息。
Our prompting strategy focuses on instilling good heuristics rather than rigid rules. We studied how skilled humans approach research tasks and encoded these strategies in our prompts—strategies like decomposing difficult questions into smaller tasks, carefully evaluating the quality of sources, adjusting search approaches based on new information, and recognizing when to focus on depth (investigating one topic in detail) vs. breadth (exploring many topics in parallel). We also proactively mitigated unintended side effects by setting explicit guardrails to prevent the agents from spiraling out of control. Finally, we focused on a fast iteration loop with observability and test cases.
我们的提示策略侧重于灌输优秀的启发式规则,而非僵化的规定。我们研究了熟练的人类如何处理研究任务,并将这些策略编码到我们的提示中——例如将困难问题分解为更小的任务、仔细评估信源质量、根据新信息调整搜索方法,以及识别何时应关注深度(详细研究一个主题)与广度(并行探索多个主题)。我们还通过设置明确的护栏来主动减轻意外的副作用,以防止 agent 失控。最后,我们专注于一个带有可观察性和测试用例的快速迭代循环。
Effective evaluation of agents 有效评估 agent
Good evaluations are essential for building reliable AI applications, and agents are no different. However, evaluating multi-agent systems presents unique challenges. Traditional evaluations often assume that the AI follows the same steps each time: given input X, the system should follow path Y to produce output Z. But multi-agent systems don’t work this way. Even with identical starting points, agents might take completely different valid paths to reach their goal. One agent might search three sources while another searches ten, or they might use different tools to find the same answer. Because we don’t always know what the right steps are, we usually can’t just check if agents followed the “correct” steps we prescribed in advance. Instead, we need flexible evaluation methods that judge whether agents achieved the right outcomes while also following a reasonable process.
好的评估是构建可靠 AI 应用的基石,agent 系统亦然。然而,评估 multi-agent 系统存在其独特的挑战。传统评估通常假设 AI 每次都遵循相同的步骤:给定输入 X,系统应遵循路径 Y 以产生输出 Z。但 multi-agent 系统并非如此运作。即便起点相同,不同的 agent 也可能通过完全不同的有效路径达成目标。一个 agent 可能检索了三个信源,而另一个则可能检索了十个;它们也可能使用不同的工具找到同一个答案。因为我们无法预知所有正确的步骤,所以不能简单地检查 agent 是否遵循了我们预设的“正确”流程。我们需要的是一种更灵活的评估方法,它既能判断 agent 是否达成了正确的结果,又能评估其过程的合理性。
Start evaluating immediately with small samples. 立即从小样本开始评估
In early agent development, changes tend to have dramatic impacts because there is abundant low-hanging fruit. A prompt tweak might boost success rates from 30% to 80%. With effect sizes this large, you can spot changes with just a few test cases. We started with a set of about 20 queries representing real usage patterns. Testing these queries often allowed us to clearly see the impact of changes. We often hear that AI developer teams delay creating evals because they believe that only large evals with hundreds of test cases are useful. However, it’s best to start with small-scale testing right away with a few examples, rather than delaying until you can build more thorough evals.
在 agent 开发的早期,改动往往会产生巨大影响,因为有大量唾手可得的改进空间。一个简单的提示调整可能会将成功率从 30% 提升到 80%。在这种巨大的效果量下,你只需几个测试用例就能发现变化。我们从大约 20 个代表真实使用模式的查询集开始。测试这些查询常常让我们能清楚地看到改动的影响。我们经常听到 AI 开发团队推迟创建评估,因为他们认为只有包含数百个测试用例的大型评估才有用。然而,最好是立即从少量示例的小规模测试开始,而不是等到能够构建更全面的评估时再行动。
LLM-as-judge evaluation scales when done well. LLM-as-judge:一种可规模化的有效评估方法
Research outputs are difficult to evaluate programmatically, since they are free-form text and rarely have a single correct answer. LLMs are a natural fit for grading outputs. We used an LLM judge that evaluated each output against criteria in a rubric: factual accuracy (do claims match sources?), citation accuracy (do the cited sources match the claims?), completeness (are all requested aspects covered?), source quality (did it use primary sources over lower-quality secondary sources?), and tool efficiency (did it use the right tools a reasonable number of times?). We experimented with multiple judges to evaluate each component, but found that a single LLM call with a single prompt outputting scores from 0.0-1.0 and a pass-fail grade was the most consistent and aligned with human judgements. This method was especially effective when the eval test cases did have a clear answer, and we could use the LLM judge to simply check if the answer was correct (i.e. did it accurately list the pharma companies with the top 3 largest R&D budgets?). Using an LLM as a judge allowed us to scalably evaluate hundreds of outputs.
研究成果很难通过程序化方式评估,因为它们是自由格式的文本,且很少有单一的正确答案。LLM 非常适合对输出进行评分。我们使用了一个 LLM 评判者,它根据一套评分标准来评估每个输出:事实准确性(声明是否与来源匹配?)、引用准确性(引用的来源是否与声明匹配?)、完整性(所有请求的方面是否都涵盖了?)、信源质量(它是否使用了主要信源而非质量较低的次要信源?),以及工具效率(它是否以合理的次数使用了正确的工具?)。我们尝试了多个评判者来评估每个组件,但发现使用单个 LLM 调用和单个提示输出 0.0-1.0 的分数以及一个通过/不通过的等级,这种方式最为一致且与人类判断相符。当评估测试用例确实有明确答案时,这种方法尤其有效,我们可以使用 LLM 评判者简单地检查答案是否正确(例如,它是否准确列出了研发预算排名前三的制药公司?)。使用 LLM 作为评判者使我们能够规模化地评估数百个输出。
Human evaluation catches what automation misses. 人工评估捕捉自动化之遗漏
People testing agents find edge cases that evals miss. These include hallucinated answers on unusual queries, system failures, or subtle source selection biases. In our case, human testers noticed that our early agents consistently chose SEO-optimized content farms over authoritative but less highly-ranked sources like academic PDFs or personal blogs. Adding source quality heuristics to our prompts helped resolve this issue. Even in a world of automated evaluations, manual testing remains essential.
测试人员能发现评估遗漏的边缘案例。这些案例包括在不寻常查询中产生的幻觉答案、系统故障或微妙的信源选择偏见。在我们的案例中,人类测试者注意到,我们早期的 agent 总是选择经过 SEO 优化的内容农场,而不是像学术 PDF 或个人博客这样更权威但排名较低的信源。向我们的提示中添加信源质量的启发式规则帮助解决了这个问题。即使在自动化评估的世界里,手动测试仍然至关重要。
Multi-agent systems have emergent behaviors, which arise without specific programming. For instance, small changes to the lead agent can unpredictably change how subagents behave. Success requires understanding interaction patterns, not just individual agent behavior. Therefore, the best prompts for these agents are not just strict instructions, but frameworks for collaboration that define the division of labor, problem-solving approaches, and effort budgets. Getting this right relies on careful prompting and tool design, solid heuristics, observability, and tight feedback loops. See the open-source prompts in our Cookbook for example prompts from our system.
multi-agent 系统具有涌现行为,这种行为是在没有特定编程的情况下产生的。例如,对主 agent 的微小改动可能会不可预测地改变子 agent 的行为。成功需要理解交互模式,而不仅仅是个别 agent 的行为。因此,最适合这些 agent 的提示不仅仅是严格的指令,更是定义了劳动分工、解题方法和资源预算的协作框架。要做到这一点,依赖于仔细的提示和工具设计、可靠的启发式方法、可观察性以及紧密的反馈循环。请参阅我们《Cookbook》中的开源提示,以获取我们系统的示例提示。
Production reliability and engineering challenges 生产环境的可靠性与工程挑战
In traditional software, a bug might break a feature, degrade performance, or cause outages. In agentic systems, minor changes cascade into large behavioral changes, which makes it remarkably difficult to write code for complex agents that must maintain state in a long-running process.
在传统软件中,一个 bug 可能会破坏一个功能、降低性能或导致服务中断。而在 agent 系统中,微小的变化会级联成大的行为变化,这使得为必须在长时间运行过程中保持状态的复杂 agent 编写代码变得异常困难。
Agents are stateful and errors compound. agent 具有状态性,错误会层层叠加。
Agents can run for long periods of time, maintaining state across many tool calls. This means we need to durably execute code and handle errors along the way. Without effective mitigations, minor system failures can be catastrophic for agents. When errors occur, we can’t just restart from the beginning: restarts are expensive and frustrating for users. Instead, we built systems that can resume from where the agent was when the errors occurred. We also use the model’s intelligence to handle issues gracefully: for instance, letting the agent know when a tool is failing and letting it adapt works surprisingly well. We combine the adaptability of AI agents built on Claude with deterministic safeguards like retry logic and regular checkpoints.
agent 可以长时间运行,在多个工具调用之间保持状态。这意味着我们需要持久地执行代码并处理沿途的错误。如果没有有效的缓解措施,轻微的系统故障对 agent 来说可能是灾难性的。当错误发生时,我们不能仅仅从头开始重启:重启既昂贵又让用户沮丧。相反,我们构建了可以从 agent 出错时所在位置恢复的系统。我们还利用模型的智能来优雅地处理问题:例如,让 agent 知道某个工具正在失灵并让它自行适应,这种做法效果出奇地好。我们将基于 Claude 构建的 AI agent 的适应性与确定性的安全措施(如重试逻辑和定期检查点)相结合。
Debugging benefits from new approaches. 新的调试范式至关重要
Agents make dynamic decisions and are non-deterministic between runs, even with identical prompts. This makes debugging harder. For instance, users would report agents “not finding obvious information,” but we couldn’t see why. Were the agents using bad search queries? Choosing poor sources? Hitting tool failures? Adding full production tracing let us diagnose why agents failed and fix issues systematically. Beyond standard observability, we monitor agent decision patterns and interaction structures—all without monitoring the contents of individual conversations, to maintain user privacy. This high-level observability helped us diagnose root causes, discover unexpected behaviors, and fix common failures.
agent 会做出动态决策,并且在不同运行之间是非确定性的,即便提示完全相同。这使得调试更加困难。例如,用户会报告 agent “没有找到明显的信息”,但我们看不出原因。是 agent 使用了糟糕的搜索查询?选择了差劲的信源?还是遇到了工具故障?增加全面的生产环境追踪让我们能够诊断 agent 失败的原因,并系统性地修复问题。除了标准的可观察性,我们还监控 agent 的决策模式和交互结构——所有这些都在不监控单个对话内容的前提下进行,以维护用户隐私。这种高层次的可观察性帮助我们诊断根本原因,发现意外行为,并修复常见故障。
Deployment needs careful coordination. 部署需要仔细协调
Agent systems are highly stateful webs of prompts, tools, and execution logic that run almost continuously. This means that whenever we deploy updates, agents might be anywhere in their process. We therefore need to prevent our well-meaning code changes from breaking existing agents. We can’t update every agent to the new version at the same time. Instead, we use rainbow deployments to avoid disrupting running agents, by gradually shifting traffic from old to new versions while keeping both running simultaneously.
agent 系统是高度状态化的,由提示、工具和执行逻辑构成的网络,几乎持续不断地运行。这意味着每当我们部署更新时,agent 可能处于其流程的任何位置。因此,我们需要防止我们出于善意的代码更改破坏现有的 agent。我们不能同时将每个 agent 更新到新版本。相反,我们使用“彩虹部署”(rainbow deployments)来避免干扰正在运行的 agent,通过逐渐将流量从旧版本转移到新版本,同时保持两者并行运行。
Synchronous execution creates bottlenecks. 同步执行会造成瓶颈
Currently, our lead agents execute subagents synchronously, waiting for each set of subagents to complete before proceeding. This simplifies coordination, but creates bottlenecks in the information flow between agents. For instance, the lead agent can’t steer subagents, subagents can’t coordinate, and the entire system can be blocked while waiting for a single subagent to finish searching. Asynchronous execution would enable additional parallelism: agents working concurrently and creating new subagents when needed. But this asynchronicity adds challenges in result coordination, state consistency, and error propagation across the subagents. As models can handle longer and more complex research tasks, we expect the performance gains will justify the complexity.
目前,我们的主 agent 同步执行子 agent,等待每组子 agent 完成后再继续。这简化了协调,但在 agent 之间的信息流动中造成了瓶颈。例如,主 agent 无法引导子 agent,子 agent 无法相互协调,整个系统可能因为等待单个子 agent 完成搜索而被阻塞。异步执行将能够实现额外的并行性:agent 可以并发工作,并在需要时创建新的子 agent。但这种异步性在结果协调、状态一致性和跨子 agent 的错误传播方面增加了挑战。随着模型能够处理更长、更复杂的研究任务,我们预计性能的提升将使其复杂性变得物有所值。
Conclusion 结论
When building AI agents, the last mile often becomes most of the journey. Codebases that work on developer machines require significant engineering to become reliable production systems. The compound nature of errors in agentic systems means that minor issues for traditional software can derail agents entirely. One step failing can cause agents to explore entirely different trajectories, leading to unpredictable outcomes. For all the reasons described in this post, the gap between prototype and production is often wider than anticipated.
在构建 AI agent 的过程中,“最后一公里”往往会占据整个旅程的大半。在开发者机器上运行良好的代码库,要转化为可靠的生产系统,需要大量的工程投入。agent 系统的复合性错误意味着,传统软件中的小问题可能会让 agent 完全脱轨。一步失败可能导致 agent 探索完全不同的轨迹,从而导致不可预测的结果。由于本文中描述的所有原因,原型与生产之间的差距往往比预期的要大。
Despite these challenges, multi-agent systems have proven valuable for open-ended research tasks. Users have said that Claude helped them find business opportunities they hadn’t considered, navigate complex healthcare options, resolve thorny technical bugs, and save up to days of work by uncovering research connections they wouldn’t have found alone. Multi-agent research systems can operate reliably at scale with careful engineering, comprehensive testing, detail-oriented prompt and tool design, robust operational practices, and tight collaboration between research, product, and engineering teams who have a strong understanding of current agent capabilities. We’re already seeing these systems transform how people solve complex problems.
尽管面临这些挑战,multi-agent 系统在开放式研究任务中已被证明具有价值。用户表示,Claude 帮助他们发现了未曾考虑的商业机会,导航复杂的医疗选项,解决棘手的技术 bug,并通过揭示他们独自无法发现的研究联系节省了多达数天的工作时间。通过精心的工程设计、全面的测试、注重细节的提示和工具设计、稳健的运营实践,以及对当前 agent 能力有深刻理解的研究、产品和工程团队之间的紧密合作,multi-agent 研究系统可以在规模上可靠地运行。我们已经看到这些系统正在改变人们解决复杂问题的方式。

Acknowlegements 致谢
Written by Jeremy Hadfield, Barry Zhang, Kenneth Lien, Florian Scholz, Jeremy Fox, and Daniel Ford. This work reflects the collective efforts of several teams across Anthropic who made the Research feature possible. Special thanks go to the Anthropic apps engineering team, whose dedication brought this complex multi-agent system to production. We’re also grateful to our early users for their excellent feedback.’
撰写者:Jeremy Hadfield、Barry Zhang、Kenneth Lien、Florian Scholz、Jeremy Fox 和 Daniel Ford。此项工作反映了 Anthropic 多个团队的共同努力,是他们使研究功能成为可能。特别感谢 Anthropic 应用工程团队,他们的奉献将这个复杂的 multi-agent 系统带到了生产环境。我们也感谢早期用户的宝贵反馈。
Appendix 附录
Below are some additional miscellaneous tips for multi-agent systems.
以下是一些关于 multi-agent 系统的额外杂项提示。
End-state evaluation of agents that mutate state over many turns. 多轮交互中改变状态的 agent 的终态评估
Evaluating agents that modify persistent state across multi-turn conversations presents unique challenges. Unlike read-only research tasks, each action can change the environment for subsequent steps, creating dependencies that traditional evaluation methods struggle to handle. We found success focusing on end-state evaluation rather than turn-by-turn analysis. Instead of judging whether the agent followed a specific process, evaluate whether it achieved the correct final state. This approach acknowledges that agents may find alternative paths to the same goal while still ensuring they deliver the intended outcome. For complex workflows, break evaluation into discrete checkpoints where specific state changes should have occurred, rather than attempting to validate every intermediate step.
评估那些在多轮对话中修改持久状态的 agent 面临独特挑战。与只读的研究任务不同,每个动作都可能改变后续步骤的环境,从而产生传统评估方法难以处理的依赖关系。我们发现,专注于终态评估而非逐轮分析取得了成功。我们不判断 agent 是否遵循了特定过程,而是评估其是否达到了正确的最终状态。这种方法承认 agent 可能找到通向同一目标的不同路径,同时仍确保其达成预期结果。对于复杂的工作流程,应将评估分解为特定的离散检查点,在这些点上特定的状态变化应该已经发生,而不是试图验证每一个中间步骤。
Long-horizon conversation management. 长程对话管理
Production agents often engage in conversations spanning hundreds of turns, requiring careful context management strategies. As conversations extend, standard context windows become insufficient, necessitating intelligent compression and memory mechanisms. We implemented patterns where agents summarize completed work phases and store essential information in external memory before proceeding to new tasks. When context limits approach, agents can spawn fresh subagents with clean contexts while maintaining continuity through careful handoffs. Further, they can retrieve stored context like the research plan from their memory rather than losing previous work when reaching the context limit. This distributed approach prevents context overflow while preserving conversation coherence across extended interactions.
生产环境的 agent 经常参与跨越数百轮的对话,需要精心设计的上下文管理策略。随着对话的延长,标准的上下文窗口变得不足,这就需要智能压缩和记忆机制。我们实施了这样的模式:agent 在完成工作阶段后进行总结,并将关键信息存储在外部记忆中,然后再进入新任务。当接近上下文限制时,agent 可以生成具有干净上下文的新子 agent,同时通过谨慎的交接保持连续性。此外,它们可以从记忆中检索存储的上下文(如研究计划),而不是在达到上下文限制时丢失之前的工作。这种分布式方法既防止了上下文溢出,又在长时间的互动中保持了对话的连贯性。
Subagent output to a filesystem to minimize the ‘game of telephone.’ 为减少“传话游戏”效应,子 agent 将输出直接传至文件系统
Direct subagent outputs can bypass the main coordinator for certain types of results, improving both fidelity and performance. Rather than requiring subagents to communicate everything through the lead agent, implement artifact systems where specialized agents can create outputs that persist independently. Subagents call tools to store their work in external systems, then pass lightweight references back to the coordinator. This prevents information loss during multi-stage processing and reduces token overhead from copying large outputs through conversation history. The pattern works particularly well for structured outputs like code, reports, or data visualizations where the subagent’s specialized prompt produces better results than filtering through a general coordinator.
特定类型的结果可通过直接的子 agent 输出绕过主协调器,从而提升保真度与性能。我们不强制子 agent 通过主导 agent 传递所有信息,而是采用工件(artifact)系统,使专业 agent 能独立生成并保存输出。子 agent 调用工具将工作存储于外部系统,随后向协调器回传轻量级引用。此方法避免了多阶段处理中的信息丢失,并减少了因通过对话历史记录复制大段输出而产生的 token 开销。该模式尤其适用于代码、报告或数据可视化等结构化输出,此时子 agent 的专业提示能产生比通过一般协调器过滤更优的结果。
 wechat
wechat alipay
alipay